Рисунок 1. Структура связей UPA.
Прежде чем переходить к рассмотрению архитектуры семейства компьютеров Ultra (часто ее называют Ultra-архитектура), необходимо уяснить, как она соотносится с архитектурой SPARC. В противном случае может возникнуть впечатление, что произошла замена одной архитектуры другой, что не соответствует действительности.
Аббревиатура SPARC происходит от словосочетания Scaleable Processor ARChitecture (масштабируемая архитектура процессоров). Данный термин относится к семейству микропроцессоров, появившемуся в 1987 году. Однако, как часто бывает, понятие SPARC постепенно стало ассоциироваться с архитектурой самих компьютеров, производимых фирмой. Следует признать, что в определенном смысле это оправданно, поскольку при разработке и компьютеров, и микропроцессоров использовались общие требования и подходы. К ним относятся высокая производительность и экономичность, масштабируемость (в широком понимании этого слова), ориентация на открытые стандарты, а также наличие мощной программной поддержки.
Именно поэтому, когда в начале 90-х годов руководством Sun Microsystems было принято решение о создании компьютеров нового поколения, речь шла о продолжении традиций и воплощении перечисленных принципов на новом технологическом уровне, с учетом выявившихся тенденций развития вычислительной техники. Поскольку SPARC-архитектура микропроцессоров полностью подтвердила свою жизнеспособность, то основное внимание было сконцентрировано на разработке новой архитектуры компьютеров, которая получила название Ultra, что, по-видимому, должно обозначать ее превосходство над предшественниками и конкурентами.
Разработка велась по трем основным направлениям:
В ходе работы были использованы и некоторые другие технические решения, на которых мы также остановимся.
Не углубляясь в технические детали, ограничимся кратким описанием особенностей данного микропроцессора.
Новая серия микропроцессоров представляет собой уже девятую версию архитектуры SPARC (SPARC Version 9). Эта версия включила в себя наибольшее количество изменений с момента появления первых микропроцессоров SPARC. В список новшеств входят:
и некоторые другие.
При всем многообразии перечисленных нововведений наиболее важными представляются следующие два:
Микропроцессоры UltraSPARC являются первыми представителями семейства SPARC, обладающими этим свойством. К моменту их появления процессоры с той же разрядностью уже имели такие известные производители и разработчики микропроцессорной техники, как DEC (Alpha 21064), MIPS (R4xxx) и Hewlett Packard (HP 7200). Увеличение разрядности данных позволяет поднять производительность, а увеличение разрядности адреса снимает ограничение на размер адресуемой области памяти в 4 Гб, что стало критичным для высокопроизводительных многопроцессорных систем.
В последние несколько лет отчетливо проявилась тенденция ко все более широкому распространению мультимедийных приложений, причем речь идет не о каких-то специфических областях применения (как например, рекламное дело), а о самых обычных. Качественные звук и изображение являются непременным атрибутом компьютерных игр, да и такие серьезные приложения, как банковские или офисные, все чаще используют современные средства визуализации информации. В этой связи можно говорить о заметном увеличении доли аудио- и видеоданных в общей структуре информации, а также о существенном возрастании потоков данных, подлежащих обработке. Естественно, это требует дополнительных вычислительных ресурсов, и лучше, если эти ресурсы будут специализированными.
Компания Sun была первой, реализовавшей функции поддержки графики в кремнии, для чего был разработан дополнительный набор команд VIS. Этот набор предназначен для аппаратной поддержки двумерной и трехмерной графики, обработки аудио- и видеоданных, а также преобразования изображений. Он содержит 4 группы команд:
Использование VIS позволяет при той же частоте микропроцессора получить десятикратный выигрыш в производительности на графических задачах, причем "цена" этого составляет всего 3% от площади кристалла (именно столько места занимает графическое устройство).
Возвращаясь к общим вопросам архитектуры микропроцессора, отметим, что к настоящему моменту появилась уже третья версия кристалла — UltraSPARC-III, работающая на частоте 600 МГц, что для процессоров такой сложности представляется большим достижением.
Быстрое формирование (или преобразование) изображения еще не значит, что соответствующая картинка быстро отобразится на экране монитора, особенно если речь идет об изображении достаточно высокого качества (например, с разрешением 1280 на 1024 пиксела и палитрой в 16 миллионов одновременно отображаемых цветов). Дело в том, что между процессором, который формирует картинку, и монитором располагается видеопамять, которая накладывает на процесс визуализации некоторые ограничения, обусловленные ее внутренней архитектурой, задерживает его. С конца 80-х годов организация микросхем видеопамяти (VRAM) практически не изменилась и морально устарела. Таким образом, одна из основных компонент графической подсистемы, изначально призванная ускорять процесс формирования изображения, стала одним из самых узких мест. Это, конечно, не означает, что использование VRAM перестало быть оправданным, однако построение на ее основе современных графических подсистем становится весьма громоздким. Естественно, что перед специалистами Sun при проработке концепции нового поколения компьютеров встал вопрос о принципиальном решении данной проблемы. Такое решение было найдено.
В 1994 году фирма Mitsubishi Electronics America анонсировала свою новую архитектуру видеопамяти — 3D-RAM, которая обеспечивала увеличение производительности по сравнению с традиционной VRAM примерно в 10 раз (сравнивались скорости рисования треугольников на двух графических подсистемах) при сопоставимой стоимости. Новинка заинтересовала Sun, и в 1995 году было заключено соглашение об использовании 3D-RAM в перспективных компьютерах семейства Ultra. При этом специалисты Sun тесно сотрудничали со своими коллегами из Mitsubishi на этапе адаптации изделия под конкретные требования. Полученная в результате этой работы видеопамять позволила примерно на порядок поднять общую производительность графической подсистемы.
Из трех основных технологий, на которых основывается архитектура Ultra, вне всякого сомнения, ключевой является архитектура межсоединений UPA (Ultra Port Architecture), поскольку именно она определяет поведение потоков данных в системе. В последние годы быстрый рост производительности микропроцессоров, широкое распространение многопроцессорных систем и связанное с этим увеличение объема передаваемых данных привели к нехватке пропускной способности магистралей передачи данных (подробнее о магистралях см. во врезке "Эволюция параллельных шин"). Традиционные решения, представляющие собой общие параллельные шины, практически исчерпали свой потенциал. По крайней мере, для построения многопроцессорных систем с числом процессорных модулей больше четырех целесообразность использования таких магистралей весьма сомнительна, поскольку в зависимости от организации конкретной системы каждый добавленный процессор дает в среднем от 40 до 80 процентов прироста производительности, причем с увеличением числа процессоров эта цифра уменьшается. Пришло время новых решений, позволяющих организовать параллельную передачу данных в системе. Именно к таким технологиям относится UPA. Как можно понять из названия (Ultra Port), данная архитектура предусматривает возможность большого (теоретически неограниченного) количества коммутируемых портов.
Итак, что такое UPA?
UPA — это высокопроизводительная многошинная (многопортовая) масштабируемая архитектура, построенная на принципе одновременной пакетной коммутации нескольких портов и предназначенная для реализации широкого спектра вычислительных систем (от однопроцессорных рабочих станций до многопроцессорных серверов), имеющих оптимальное соотношение производительность/стоимость.
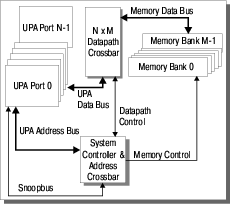
Системы, использующие архитектуру UPA, содержат всего три основных типа функциональных блоков (см. Рис. 1 ):
Эти модули связаны друг с другом посредством коммутаторов адреса и данных.
Поскольку передача данных осуществляется только между процессорами или устройствами ввода-вывода и памятью, первые два функциональных узла с точки зрения архитектуры ничем не отличаются, что и отображено на Рис. 1 (блоки, поименованные UPA-порт #N, через коммутатор данных соединяются с банками памяти #M). Поэтому часто говорят, что UPA реализует обмен данными по схеме "процессор-память". Из Рис. 1 видны и некоторые другие особенности архитектуры.
Во-первых, архитектура опирается на многошинную организацию. Имеется три основных типа шин:
Приведенная на рисунке шина SnoopBus не входит в состав основных шин архитектуры UPA.
Особое внимание следует обратить на основное отличие UPA от других технологий, которое состоит в том, что шины UPA-адреса и UPA-данных имеют свои собственные коммутаторы, и, значит, могут иметь разную топологию. Конкретный пример такой реализации будет рассмотрен при описании системы Ultra Enterprise 10000. Отметим, что понятие "многошинная организация" относится не только к спектру типов используемых магистралей, но и к их количеству.
Во-вторых, количество UPA-портов и банков памяти теоретически не ограничено. Это непосредственно связано с многошинной организацией, поскольку в идеале каждому UPA-порту или банку памяти соответствует собственная шина данных.
В-третьих, все используемые в архитектуре шины имеют соединения типа "точка-точка". Данная особенность архитектуры определяет ее быстродействие, поскольку такой тип соединения характеризуется малой длиной линий и небольшой нагрузкой на них, что позволяет поднять частоту передачи данных до величин порядка 100 МГц. Правда, необходимо оговориться, что на самом деле UPA допускает подключение к шинам до четырех устройств (в основном это касается шин адреса), и в этом смысле утверждение о соединениях "точка-точка" не совсем корректно. Однако такие подключения используются в основном при реализации шин устройств ввода-вывода; что же касается процессорных модулей, то их на одной шине располагается не более двух.
В дополнение к приведенным, архитектура UPA имеет и некоторые другие особенности, к которым относятся:
Рассмотрим перечисленные особенности более подробно, поскольку это важно для понимания Ultra-архитектуры в целом.
Масштабируемость и поддержка многопроцессорности естественно следуют из утверждения о неограниченном количестве портов и шин. По сути это означает, что UPA позволяет наращивать производительность системы за счет установки дополнительных банков памяти, модулей ввода-вывода и/или процессорных модулей. Масштабирование разрядности шин позволяет сконфигурировать систему с оптимальным соотношением производительность/стоимость. Так, в серверах начального уровня Ultra Enterprise 1 разрядность процессорной шины составляет 144 бита, шины памяти — 288 бит и шины устройств ввода-вывода — 72 бита.
Что касается симметричной многопроцессорности, то она также является естественным свойством данной архитектуры благодаря идентичности используемых процессорных узлов, наличию единого ресурса — памяти, и механизму поддержки когерентности кэша.
Пакетная передача данных является одной из основных особенностей UPA. Во врезке "Эволюция параллельных шин" говорится о преимуществах магистралей с конвейерной организацией передачи данных. Все это справедливо и для рассматриваемой архитектуры. Она по сути представляет собой набор из нескольких конвейерных шин. Ограничение на размер пересылаемого блока фиксирует время его передачи по шине и предотвращает возможность возникновения конфликтов при использовании одной и той же шины несколькими устройствами. Этому также способствует наличие буферов в коммутаторах шин данных. Аналогично передаче данных осуществляется передача специальных пакетных сообщений, выполняющих роль запросов на прерывание тех или иных устройств. Благодаря синхронности архитектуры и специфическому протоколу, временные затраты на процедуру прерывания становятся предсказуемыми.
Эволюция параллельных шин
В процессе развития вычислительной техники периодически возникала проблема исчерпания пропускной способности каналов обмена данными. На каждом этапе эта проблема решалась по-своему. Мы хотели бы, не претендуя на детальность изложения, кратко рассказать о том, какими путями развивались шины передачи данных, чтобы были понятны причины появления архитектуры UPA.
Развитие шин передачи данных тесно связано с эволюцией микропроцессорной техники. Появление микропроцессоров стимулировало разработку шинных интерфейсов. Помимо этого, у каждой компании, производящей компьютеры, существовали собственные реализации внутренних каналов обмена, поэтому в дальнейшем изложении мы не будем привязываться к каким-либо стандартам, а рассмотрим основные тенденции развития.
Первые массовые микропроцессоры имели разрядность 8 бит, что определило и организацию соответствующих шин. Кроме того, из-за дефицита количества выводов микросхем (проблема, совершенно неактуальная в наши дни) адрес и данные были мультиплексированы, что также сказалось на реализации некоторых каналов обмена данными (мультиплексированные шины требовали меньшего количества микросхем для своей реализации). В этой ситуации очевидными способами повышения производительности являлись разделение шин адреса и данных, а также увеличение разрядности.
Появление микросхем динамической памяти явилось одним из основных стимулов введения нового режима работы шин — режима блочных передач. Это позволило при том же темпе передачи данных поднять пропускную способность как минимум в полтора раза. Считается, что при пересылке отдельного слова по немультиплексированной шине времена, затрачиваемые на передачу адреса и данных, соотносятся как 3:7. При блочной передаче адрес выставляется только один раз, в начале цикла обмена. Соответственно, чем длиннее блок данных, тем меньшее время занимает передача адреса и тем выше эффективность использования шины.
Следующим нововведением было появление в протоколе микропроцессорных шин средств поддержки когерентности (согласованности) кэш-памяти. Нельзя сказать, что это сильно сказалось на производительности, однако данное качество свидетельствовало о появлении нового типа архитектуры компьютеров — симметричных многопроцессорных систем (SMP-систем), то есть систем, состоящих из однотипных (симметричных) процессорных модулей, соединенных друг с другом посредством общей шины, и имеющих единый ресурс - общую память.
Присутствие на общей шине нескольких процессоров или каких-либо других устройств, имеющих возможность инициировать обмен данными по шине, снижает эффективность ее использования. Это обусловлено необходимостью осуществления процедуры арбитрации, то есть выявления устройств, требующих предоставления шины, определения наиболее приоритетного из них и выделения ему этого ресурса. Для многопроцессорных систем существует понятие линейности. Этим термином обозначается выраженное в процентах отношение реальной производительности системы при определенном количестве процессорных элементов (процессорных модулей) к теоретическому значению, полученному путем умножения производительности однопроцессорной системы на число процессорных элементов. Обычно считается, что эта зависимость сохраняет свою линейность при числе процессоров до 4-х. При дальнейшем наращивании количества процессоров рост производительности происходит все меньшими темпами, а начиная с какого-то значения (для каждой систем оно свое) он прекращается.
Использование механизма когерентности кэш-памяти позволило снизить издержки, связанные с разрешением конфликтов при работе нескольких процессоров с разделяемой (общей) памятью.
Новый этап эволюции шин начался с появлением магистралей с конвейерной передачей данных. Впервые автор столкнулся с таким решением в начале 90-х годов в материалах DEC по макетной системе, явившейся прообразом нового поколения компьютеров с микропроцессором Alpha. Основными особенностями конвейерных магистралей являются:
- синхронность (работа шины стробируется системной частотой);
- высокая эффективность использования;
- большая пропускная способность (частота синхронизации достигает 100 МГц);
- быстрая обработка прерываний, механизм которых отличается от системы прерываний традиционных общих шин (здесь прерывания — это просто сообщения, передаваемые по магистрали, как и обычные данные).
Суть работы такой магистрали состоит в фиксации размера передаваемого блока данных (часто его выбирают равным размеру строки кэш-памяти базового микропроцессора) и четкой синхронизации циклов передачи адреса и данных (линии адреса и данных, естественно, разделены). Таким образом, процесс обмена данными разбивается на фазы, длительность и временные соотношения которых строго определены (после выставления адреса точно известно, в какой момент будет передан блок данных, и когда появится подтверждение правильности приема). Протокол обмена конвейерных магистралей позволяет осуществлять процедуры адресации и арбитрации шины параллельно передаче данных предыдущего цикла. Это дает возможность поднять эффективность использования линий данных практически до 100%. Что касается линейности систем с такими шинами, то, не имея конкретных цифр, все-таки можно утверждать, что она будет выше, чем у систем с общей шиной. Магистрали с конвейерной передачей данных используются в серверах Ultra Enterprise серии X000.
По поводу общих шин, то есть шин, линии которых (адрес, данные, арбитрация и т.п.) подключены одновременно ко всем устройствам, входящим в состав системы, можно утверждать следующее. Они просты в реализации, дешевы, надежны (не содержат активных компонент) и имеют пропускную способность, достаточную для реализации небольших SMP-систем. Однако рост их производительности возможен лишь до определенного предела, который, похоже, уже достигнут. Это связано с принципиальным ограничением на максимальную частоту синхронизации шины. В настоящее время известны магистрали, работающие на частотах до 100 МГц. Дальнейшее увеличение частоты сопряжено с проблемами корректной передачи сигналов, ограничением длины линий магистрали, искажением сигналов в зависимости от количества нагрузок и т.п. Построение высокопроизводительных многопроцессорных серверов, которым, помимо большой вычислительной мощности, требуется огромная пропускная способность магистрали, на базе общей шины представляется нереальным. Для этого требуется новый подход.
Принципиальное преодоление ограничений, которые имеют общее шины, возможно только посредством использования технологий, обеспечивающих одновременную передачу (распараллеливание) большого количества потоков данных. В настоящее время существует несколько решений такого рода, ориентированных на высокопроизводительные вычислительные комплексы:
- технологии, основанные на высокоскоростных каналах с соединениями типа "точка-точка", как, например, последовательно-параллельный интерфейс SCI (Scaleable Coherent Interface), используемый фирмой Sequent в качестве базового канала для реализации многопроцессорного комплекса (технология NUMA);
- технологии, основанные на принципе коммутации потоков данных.
Среди последних наиболее известны две:
- ServerNet фирмы Tandem;
- UPA, на принципах которой построена шина Gigaplane-XB сервера Ultra Enterprise 10000.
Из перечисленных решений понятие шины в полной мере применимо, пожалуй, только к архитектуре UPA.
Пока трудно сказать, какой подход получит наибольшее распространение, поскольку реальное использование этих технологий только началось. Однако можно утверждать, что будущее многопроцессорных систем связано именно с такими решениями.
Поддержка когерентности кэш-памяти. Поскольку UPA рассматривается как базовая архитектура для SMP-систем, то требование поддержки когерентности кэш-памяти выглядит естественным. Особенностью реализации данного требования в рассматриваемой архитектуре является централизованный контроль когерентности кэшей. Под централизованным контролем и управлением понимается наличие отдельного (логически или физически — зависит от конкретной реализации) устройства, которое отслеживает адреса, выставляемые по всем шинам, и выдает модулям сообщения о необходимости обновления содержимого кэша. Наличие такого устройства ускоряет саму процедуру, однако оно может оказаться достаточно громоздким, если система содержит большое количество модулей. Добавим, что идея централизованной обработки коснулась также и процедуры арбитрации шин, которая реализована в том же устройстве и на тех же принципах.
Последние несколько лет проблеме сохранения целостности данных уделяется достаточно много внимания. Само по себе использование битов четности или ECC-кодов не представляют ничего нового и широко распространено, в частности, при реализации каналов доступа к памяти. В данном случае интересен комплексный подход к этой проблеме, когда защищаются не только шины передачи данных, но и шины адреса, что встречается не столь часто.
Объективности ради следует отметить и некоторые узкие места в описываемой архитектуре. Прежде всего это касается вопросов наращиваемости систем. Теоретически все выглядит очень просто, однако на практике возникают довольно серьезные технические проблемы. Например, не так легко представить себе коммутатор 16-ти 144-разрядных шин данных, а ведь именно такие коммутаторы используются в сервере Ultra Enterprise 10000. Это довольно сложные устройства, состоящие из большого количества заказных микросхем. Они были разработаны специально для данного сервера и никаким изменениям не подлежат. То есть коммутатор — это устройство, данное компьютеру на всю жизнь, и прожить с ним надо так, чтобы не было мучительно больно за не лучшим образом потраченные деньги.
То же можно сказать о принципе централизованного управления работой памяти и арбитрации шин адреса и данных. С ростом системы линейно увеличивается количество шин и линий управления, связывающих модули и собственно устройство управления, что на практике может серьезно усложнить наращивание.
Другим тонким местом архитектуры представляется тот факт, что, по утверждениям специалистов компании, UPA была разработана в расчете на SMP-системы с числом процессоров не более 4-х (в данном случае под процессором понимается устройство, имеющее UPA-порт или интерфейс). Это означает, что системы с большим количеством процессоров должны либо использовать для связи какие-то другие способы и интерфейсы (как в серверах семейства Ultra Enterprise X000), либо создавать многоуровневые UPA-структуры (как в Ultra Enterprise 10000).
Помимо трех технологий, определяющих основные качества новой архитектуры, компания Sun Microsystems использовала также ряд программно-аппаратных решений, которые позволили развить заложенные в аппаратуру возможности. В число этих решений входят:
Перечисленные решения применяются преимущественно в самых мощных серверах, и поэтому о них нельзя говорить, как о качествах (параметрах, характеристиках), свойственных всему семейству Ultra. Ниже будет дано лишь их краткое описание. Более подробно они будут рассмотрены в разделе, посвященном системе Ultra Enterprise 10000.
Выше, при описании основных требований, предъявляемых к серверам, был введен термин RAS. Применительно к многопроцессорным серверам он нуждается в конкретизации и развитии. Соответствующий комплекс средств и подходов к обеспечению высокой доступности такого рода Ultra-систем получил название SunTrust. Он включает в себя следующие понятия:
Некоторые компоненты комплекса SunTrust (например, поддержка целостности передаваемых по шинам данных) применяются уже в младших моделях семейства и будут рассмотрены в соответствующих разделах.
Данное решение выделено потому, что представляет собой очень хороший пример реализации архитектуры UPA. Выше, при описании самой архитектуры, уже подчеркивалась ее специфичность. Если рассмотреть всех представителей нового семейства с точки зрения применения данной технологии, то можно увидеть следующее.
Младшие модели, имеющие не более четырех микропроцессоров, построены в точном соответствии с UPA. Более мощные модели используют эту архитектуру только на уровне процессорных модулей (по два микропроцессора на каждом модуле), связь между которыми осуществляется по общей шине Gigaplane, реализующей конвейерную передачу данных. И только самые высокопроизводительные многопроцессорные системы снабжены коммутатором Gigaplane-XB, в основу которого положена та же архитектура UPA. Таким образом, системы с Gigaplane-XB имеют двухуровневую архитектуру UPA:
Подобное решение позволяет обходить сложности, связанные с внутренними ограничениями архитектуры, о которых упоминалось выше.
К сожалению, по-русски определение DSD звучит довольно длинно: выделение динамически переконфигурируемых логических серверов (доменов) внутри многопроцессорной системы. Часто для краткости говорят о "сервере в сервере" или "системе в системе". Данное решение имеет следующие особенности:
Выделение доменов — это один из способов повышения доступности (готовности) системы. Как правило, серверы выполняют достаточно большой набор задач, в том числе критически важных. Часто, чтобы не ставить выполнение подобных приложений в зависимость от остальных, их выносят на отдельные машины. При использовании DSD необходимость в таких дорогостоящих решениях отпадает. Можно привести и другие примеры применения DSD.
Более подробно данная технология будет рассмотрена при описании сервера Ultra Enterprise 10000.

|

|

|
| Семейство компьютеров Ultra компании Sun Microsystems | Содержание | Семейство компьютеров Ultra |
| Copyright ╘ 1993-2000, Jet Infosystems |